Guided Grasp
Grasp Planning for Visual Assistive App
Min Young Chang, Eric Pu Jing, with advisor Prof. Shuran Song

Overview
The goal of this project is to create an app that can guide users’ hands to grasp an object on the tabletop without them having to see the smartphone interface. The app allows users to specify verbally which objects to target and to listen to verbally-issued commands from the app in order to grasp the target object.
Introduction
Visually-impaired individuals have long struggled to navigate a world that is designed mainly around sight. This problem has only grown with the advent of personal computers and smartphones, which pioneered the concept of a graphical user interface (GUI). Many apps available on smartphones operate on the assumption that users possess the eyesight required to perceive the user interface. There exist features that provide some measure of accessibility for the blind, though most are ad-hoc compromises that do not provide the full range of features offered by a GUI. With deep learning entering the mainstream, there are more tools available than ever to improve the quality of life of those with visual disabilities.
Among the many offerings available to developers, Apple’s ARKit provides a fully-featured set of tools that are relevant to assistive technology. Previous works such as AIGuide [1] make use of this development kit to localize objects captured via camera into a single 3D scene in order to help visually-impaired users navigate to desired objects.
The main addition to this concept is the use of a point cloud to not only aid in avoiding collisions with other objects in the scene, but also to inspect the target for points that are desirable locations to grasp. Avoiding obstacles is one task that always accompanies navigation, and this task becomes much more important when the target audience cannot rely upon vision to avoid them. Searching for a desirable location to grasp is also an important part of the overall task, as different objects may have different ways to grasp them.
Method
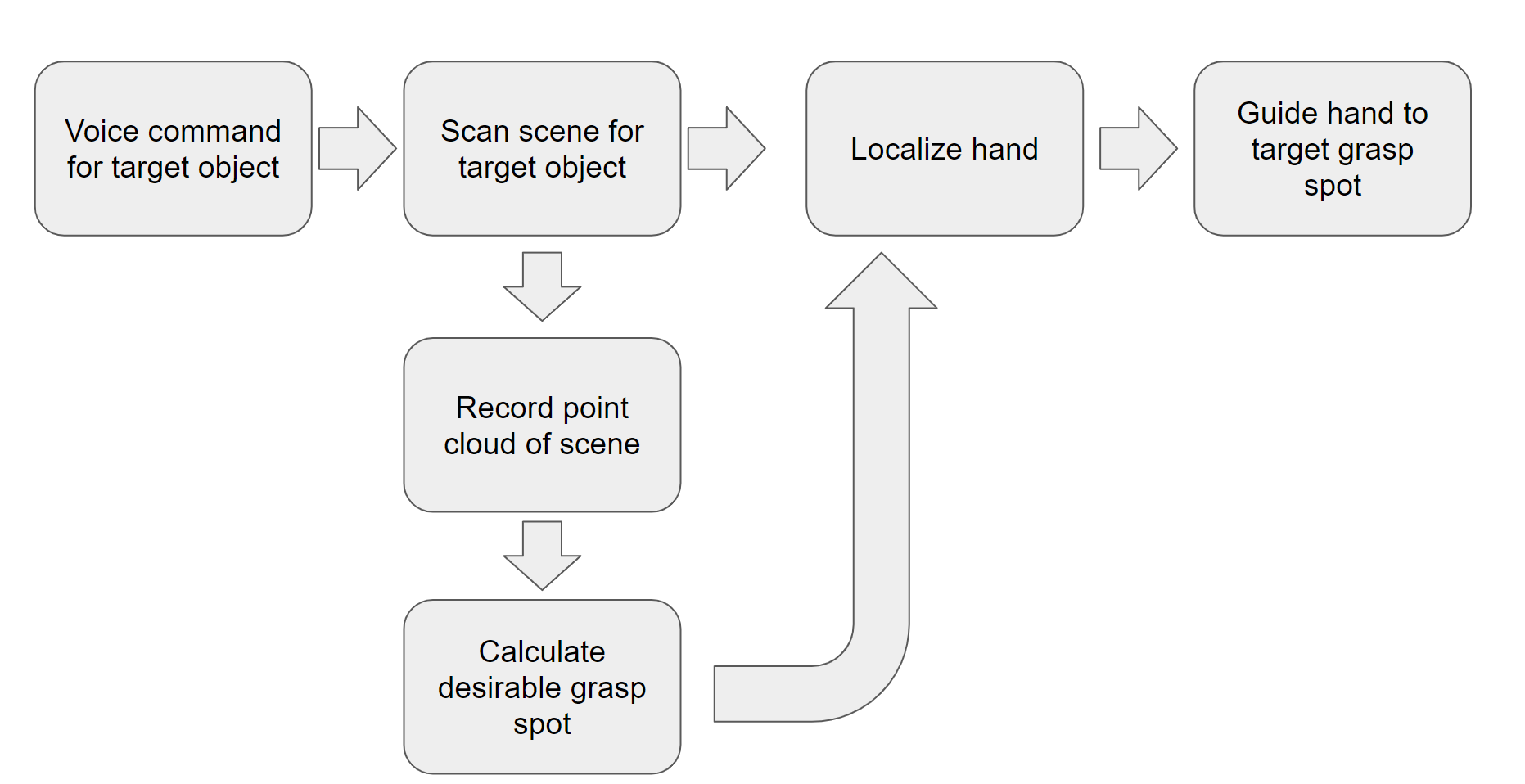
The first phase aims to provide a way for users to select what kind of object the app should detect. Because of the intended user base, the interface must be operable without the users having to look at the screen. The decision was made to use a speech recognition interface, where users would verbally communicate to the app what object it should look for. The implementation makes use of Apple’s software interface for basic speech recognition tasks. To limit the scope of the project to a more manageable size, only two possible target objects are accepted: bottle, and cup.

The second phase scans the area around the user, looking for the target object within the scene. This step uses Apple’s Vision framework to detect a bounding box of the object from the camera footage. Previously considered ideas for object localization involving point clouds were discarded in favor of directly using the phone’s visual feed. While effective, performance suffered when dealing with more complex scenes, such as with a transparent table. While the app looks for the target, it also scans and saves a sparse point cloud using ARKit. During the development process, attempts were made to obtain a dense point cloud from the phone’s LiDAR depth map, but the limited computing resources of the phone made such an avenue impractical.

Once the object has been detected, a subset of points in the point cloud is assigned to the object, based on the location of the sub-image containing the target object. From those points a list of scores is computed, using a depth map provided by the iPhone’s LIDAR functionality. By applying a filter over the depth map using the Metal hardware acceleration framework, a texture containing the desirability of potential grasping positions is obtained. The point whose corresponding score is the highest becomes a candidate grasping point.

The third phase detects the hand of the current user and guides it toward the target object. Using Apple’s Vision framework, the position of the hand’s center can be determined from the iPhone’s camera footage. Once the position of the hand has been determined relative to the target object, the app then issues verbal commands to guide the hand to the target object. If the path between the object and the hand is obstructed, the app will issue a warning that the hand is about to collide with an obstacle. Once the hand is sufficiently close to the target, the app will announce that the guiding phase is complete.